The implementation of AI databases with branch-leaf architectures on VAST is a game-changer for machine learning pipelines:
Linear Scalability
- Traditional databases struggle to scale as datasets grow. Implementing AI databases overcome this by distributing data and compute across thousands of CPUs, maintaining consistent performance as the system scales.
- VAST DB enables the AI Database and ensures that even with 1,000+ branches, each backed by unique database schemas and tables, the architecture remains performant and responsive.
Massive Parallelism
- AI databases are optimized for massive parallelism, seamlessly handling millions of transactions per second.
- VAST DB enables the creation of advanced decision tree branch-leaf architectural models. This parallelism allows for independent, concurrent queries across all branches, ensuring near-instantaneous insights regardless of data volume.
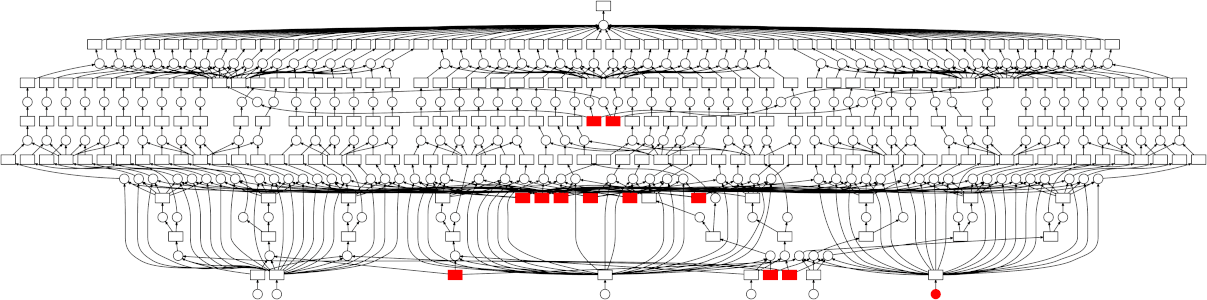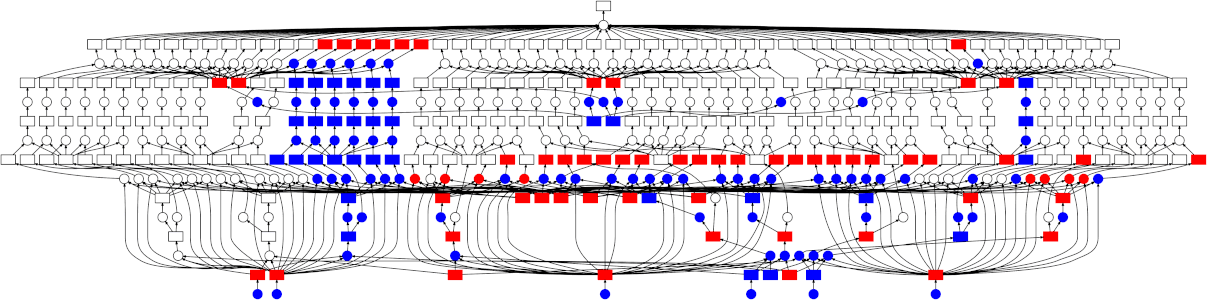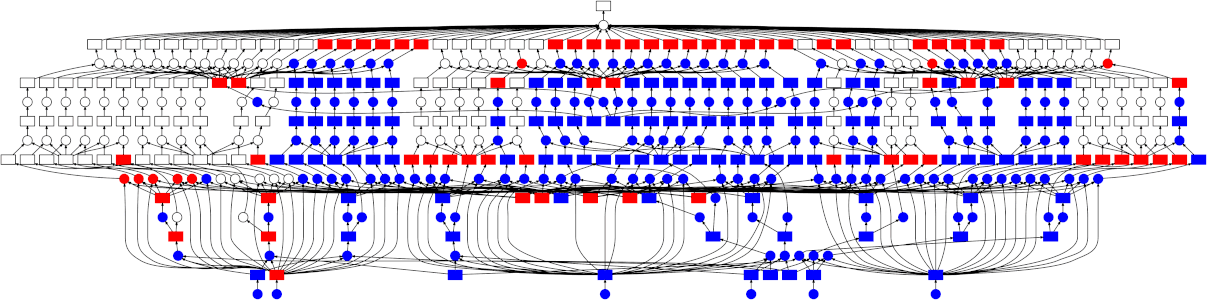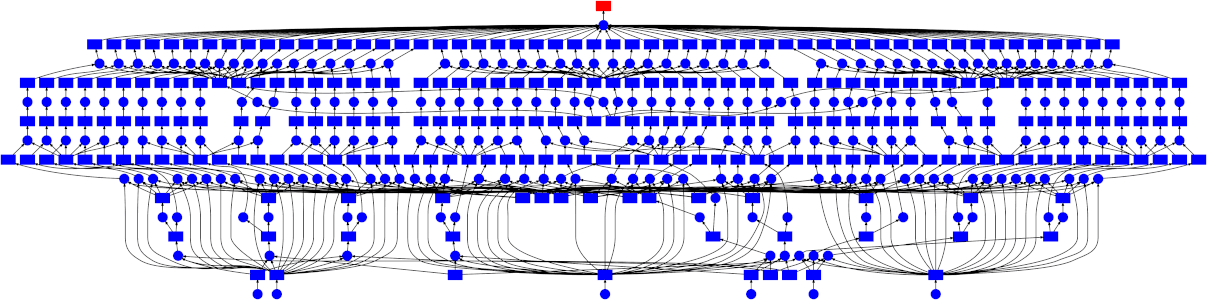
VASTified Branch-Leaf Decision Trees
Branches: Represent decision points and are implemented as a db
Leaf Nodes: Represent unique schemas and tables, each tailored to the specific classification.
- Each branch is a high throughput network citizen and can be queried independently, ensuring branch leaf decision trees exhibit symmetric performance across concurrent queries.
- Each leaf node therefore exhibits linear scalability and parallelism to handle queries on specialized data at breathtaking speeds.
Concurrency
- Distributed query engines like Trino deliver high performance by exploiting independent queries across all branches simultaneously.
- By parallelizing predictions, the system achieves a level of performance that traditional architectures cannot match.
Contextual Recommendation Systems
- Context: Complex recommendation engines. For example those used by Netflix, Amazon, or Spotify involve a large number of factors—user preferences, historical behavior, content features, seasonal trends, and much more. A decision tree with thousands of branches and leaves can be used to segment these decision-making processes. Let’s explore a possible branch leaf implementation:
- Branch: A branch can represent different recommendation models or stages of the recommendation pipeline (e.g., filtering by user profile, genre, content type).
- Leaf: Each leaf may represent final recommendation results, or a list of personalized items tailored to the user’s profile and context.
- Real-time decision-making: Complex decision trees allow for fine-grained, fast decision-making by breaking down the problem into smaller, easily solvable subproblems.
- Optimized personalization: Thousands of possible user segments and preferences can be represented in the tree, allowing for more personalized and accurate recommendations.
- Efficient multi-step evaluation: With proper indexing and tree traversal strategies a VASTified Decision Tree Database topology can evaluate millions of potential recommendations in a fraction of the time.
AI Data is what you should be storing
Storing data with its context — as part of a massively parallel decision tree architecture — offers numerous performance benefits and is the future of AI data. AI Data:
- Enables Real-time decision-making with instant access to contextual data.
- Improves data integrity, with no risk of context loss or transformation errors.
- Simplifies data management, reducing the need for complex ETL pipelines.
- Supports Dynamic, context-aware querying, allowing for deeper insights and provides greater transparency and explainability of AI and machine learning decisions.
- Is Adaptive for continuous, self-learning systems.
- Massive parallel, which enables high-throughput and low-latency processing.
- Built in Data provenance, supporting better governance and auditing.
By embedding the context directly into the data, you transform your data system from a static, transformation-dependent one into a highly dynamic, adaptive, and scalable system that can support real-time, intelligent decision-making at massive scale.